-
18일차 - 서브쿼리, 조인, 집합프로그래밍 언어/데이터베이스(SQL, MARIADB) 2024. 2. 16. 13:31
서브쿼리
서브쿼리는 쿼리 안의 쿼리라는 뜻이다
사전에 추출된 내용에서 재 검색하거나, 검색된 내용을 가상의 컬럼을 만들어 추가할 수 있다
서브쿼리를 사용하는 이유
■ 추출된 결과에서 재 검색할시 유용하다
■ 검색된 내용을 가상의 컬럼으로 한눈에 알기 쉽게 확인할 수 있다
□ 서브쿼리가 길어지고, 많아질수록 코드가 복잡해져 어떤 결과를 조회하는지 알기 어려워진다
서브쿼리 종류
■ 단일 행 서브쿼리, 결과는 반드시 한행으로만 조회해야한다 안그러면 오류 발생
■ 다중 행 서브쿼리, IN, ALL 등 으로 여러 개의 행을 조건절을 사용할 수 있다
서브쿼리 위치
■ SELECT 문에서 조회되는 컬럼에 위치하면, 새로운 컬럼으로 조회된다
■ 참조하려는 테이블에 위치하면, 별칭을 붙여주면 테이블처럼 조회되어 조회된다
■ 조건절에서는 단행, 다중행으로 나뉘어 적절하게 조건의 피연산자로 사용할 수 있다
더보기서브쿼리 관련한 다섯 문제 풀이
-- 서브쿼리 : 쿼리안의 쿼리 -- 하나의 쿼리문으로 받아온 데이터를 바탕으로 다른 내용을 검색할 때 -- 1) 추출된 결과로 다른 내용을 검색시 -- 2) 검색된 내용을 가상의 컬럼으로 볼 때 create table dept(-- 부서 deptno varchar(10) primary key ,deptname varchar(20) ,loc varchar(10) ); create table emp(-- 사원 ename varchar(20) ,job varchar(50) ,deptno varchar(10) ,hiredate date ); alter table emp add constraint foreign key(deptno) references dept(deptno); select * from information_schema.TABLE_CONSTRAINTS where TABLE_NAME = 'emp'; desc emp; insert into dept(deptno, deptname, loc) values('1', 'sales', 'newyork'); insert into dept(deptno, deptname, loc) values('2', 'dev01', 'LA'); insert into dept(deptno, deptname, loc) values('3', 'personnel', 'newyork'); insert into dept(deptno, deptname, loc) values('4', 'delevery', 'boston'); select * from dept; insert into emp(ename, job, deptno, hiredate) values('kim', 'manager', '1', str_to_date('16/01/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('lee', 'staff', '1', str_to_date('15/01/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('han', 'staff', '1', str_to_date('16/03/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('kim', 'assistant', '1', str_to_date('15/09/22', '%Y/%m/%d')); select * from emp; delete from emp; insert into emp(ename, job, deptno, hiredate) values('ahn', 'staff', '2', str_to_date('15/11/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('hwang', 'manager', '2', str_to_date('15/08/12', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('cha', 'assistant', '2', str_to_date('12/03/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('hong', 'staff', '2', str_to_date('14/08/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('gang', 'staff', '2', str_to_date('10/01/02', '%Y/%m/%d')); insert into emp(ename, job, deptno, hiredate) values('name', 'leader', '4', str_to_date('10/01/02', '%Y/%m/%d')); /* * 문제 */ -- 문제 1> 'han' 이라는 직원의 근무 부서는 어디인가? select * from dept; select * from emp; -- emp 테이블에서 han의 deptno 를 알아낸다 -- 알아낸 deptno 를 통해 dept 테이블에서 deptname 를 알아낸다 select deptno from emp where ename = 'han'; -- 1 select deptname from dept where deptno = '1'; -- 결국에는 쿼리 안에 쿼리를 넣게 되면 문법에 어긋난다 -- 소괄호에 쿼리를 넣어 쿼리 안에 쿼리를 구현할 수 있다 select deptname, loc from dept where deptno = (select deptno from emp where ename = 'han'); -- 문제 2> 부서 위치가 'la' 또는 'boston' 인 부서 소속의 직원들의 이름과 직책을 나타내시오 -- dept 테이블에서 loc 컬럼에서 la 또는 boston 레코드들을 추려낸다 -- la 에 위치한 부서 번호는 2번, boston 은 4번이다(la,boston 에 위치한 부서는 여러개일수도 있다) -- 부서 번호(deptno)를 통해 emp 테이블에서 2 또는 4 인 직원들의 목록을 구할 수 있다 select deptno from dept where loc in ('la', 'boston'); select ename, job from emp where deptno in ('2','4'); -- 해결 > select ename, job from emp where deptno in (select deptno from dept where loc in ('la', 'boston')); -- 문제 3> sales 부서에 근무하는 사원 데이터 (ename, job, hiredate) 가져오기 select * from dept; -- dept 테이블을 조회해본 결과에서 sales 부서의 번호는 1번이다 -- emp 테이블에서 부서 번호가 1번인 사원(staff) 목록을 가져온다 select deptno from dept where deptname = 'sales'; select ename, job, hiredate from emp where deptno = '1' && job = 'staff'; -- 해결 > -- deptno 가 몇번이야? 물어봤지만 하나의 컬럼을 물어봤는데 3개의 컬럼을 넘겨줘버린 상황이다 select ename, job. hiredate from emp where deptno = (select deptno from dept where deptname = 'sales'); -- 문제 4> 직책(job)이 manager 인 사원들(여러명일 경우 빠른 직원 기준)보다 입사일이 빠른 직원(ename, job, hiredate) 은? -- 최고참 매니저보다 빠르게 입사한 사람을 찾아라 -- emp 테이블 에서 직책인 매니저인 직원들 중 가장 빨리 입사한 날짜를 조회한다 -- 하지만 ★ 가장 빨리 입사한 날짜만 조회해야한다 -- 모든 직원들 중에서 기준 날짜보다 먼저 입사한 직원들의 목록을 조회한다 select ename,hiredate from emp where job = 'manager' order by hiredate; select * from emp where hiredate < '2015-08-12' order by hiredate; -- 1) LIMIT [가져올 레코드의 갯수] select * from emp where hiredate < (select hiredate from emp where job = 'manager' order by hiredate limit 1) order by hiredate; -- 2) MIN -- 대상 컬럼에서 최소값을 가지는 레코드를 반환한다 select * from emp where hiredate < (select min(hiredate) from emp where job = 'manager') order by hiredate; -- 문제 5> 부서별(deptno, deptname)로 직원이 몇명인지 확인 -- 쿼리가 된 내용이 조건에 쓰였지만 -- 상하 관계 쿼리 -- 서브쿼리의 결과물이 본 쿼리의 일부로 사용 될 경우 -- 컬럼, 테이블로 활용이 된다 select * from dept; select * from emp; select count(deptno) from emp where deptno = 1; -- 4 select count(deptno) from emp where deptno = 2; -- 5 select count(deptno) from emp where deptno = 4; -- 1 select deptno, deptname from dept where deptno = 1; -- 1 : sales select deptno, deptname from dept where deptno = 2; -- 2 : dev01 select deptno, deptname from dept where deptno = 4; -- 4 : delevery select deptno, deptname, (select count(deptno) from emp where deptno = 1) as cnt from dept where deptno = 1; select deptno, deptname, (select count(deptno) from emp where deptno = 2) as cnt from dept where deptno = 2; select deptno, deptname, (select count(deptno) from emp where deptno = 4) as cnt from dept where deptno = 4; -- 해결 > select deptno, deptname, (select count(deptno) from emp where deptno = d.deptno) as cnt from dept d; -- group by 활용 -- 컬럼의 없는 레코드는 그냥 조회하지 않는다 -- 상호관계 쿼리수 select deptno, count(deptno) as cnt from emp group by deptno; select deptno, count(deptno) as cnt, (select deptname from dept where deptno = e.deptno) as deptname from emp e group by deptno;
조인
■ 서브쿼리는 주로 작은 데이터셋을 처리할 때 사용되고, 대량의 데이터를 처리하기에는 한계가 있었다. 따라서 조인은 대량 데이터 처리와 다수의 테이블 간의 관계를 다룰 때 활용된다
■ 두개 이상의 테이블에서 각 테이블의 모든 행들을 조합(곱셈)하여 생성된 결과를 보여준다 이때 조합할 행을 선택하고 싶다면 on 절 뒤에 조건을 붙이면 해당되는 행들끼리만 조합된다
□ 큰 테이블끼리 사용할때 성능 문제가 발새할 수 있어 신중하게 사용해야한다
교차(CROSS) 조인
■ 행들의 모든 가능한 조합이 만들어지는 조인이다
□ 너무 많은 행들의 경우의수를 보여주기 때문에 시간이 너무 오래 걸린다
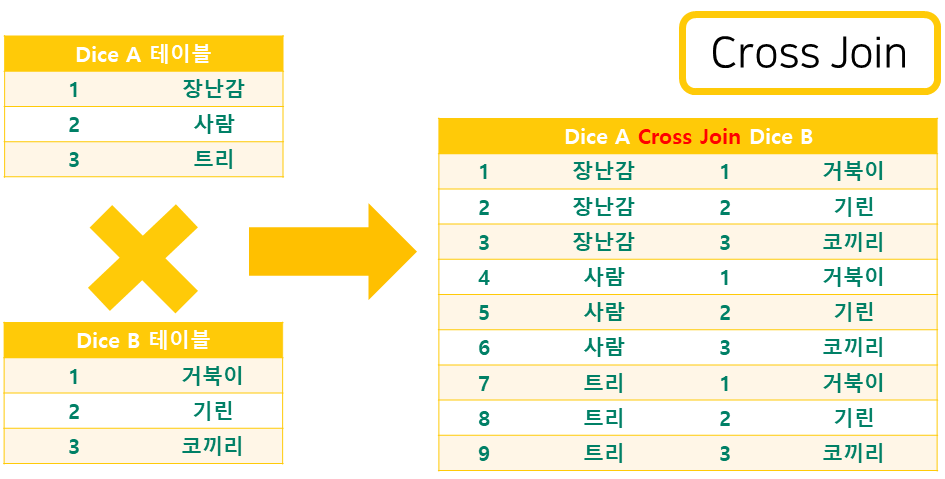
/* cross join */ -- 두개의 테이블을 카다시안 곱을 수행한다 -- 아직 정제되지 않은 순수한 상태의 조인 형태이다 -- 카다시안 곱 : 서로간의 경우의 수를 계산하는것이다 -- emp(10) * dept(4) = 40 select * from emp; select * from dept; -- FROM [table A] CROSS JOIN [table B] select e.ename, d.deptname from emp e cross join dept d; -- cross join 은 생략이 가능하다 select e.ename, d.deptname from emp e, dept d;내부 조인(Inner join)
■ 다수의 테이블간 조인 조건에 맞는 행들만을 결과를 출력하는 조인 방식을 말한다
■ FROM [table A] INNER JOIN [table B] ON [조건]
■ FROM [table A] INNER JOIN [table B] USING(조건, 컬럼 또는 서브쿼리)
□ 주의사항 1) 두 테이블의 키의 값이 같더라도 양쪽 어느 하나라도 빈값이 있으면 조회되지 않는다
-- 2) 내부 조인 -- a) FROM [table A] INNER JOIN [table B] ON [키에 대한 조건] -- inner 는 생략 가능하고, 조인을 위한 조건을 ON 뒤에 적어준다 select e.ename, d.deptname from emp e join dept d on d.deptno = e.deptno; -- using 을 사용하여 소괄호 안에 두 테이블 간의 동일한 컬럼을 넣어 -- 편리하게 등가조인을 할 수 있는 장점이 있다 -- b) FROM [table A] INNER JOIN [table B] USING(키 또는 서브쿼리) select e.ename, d.deptname from emp e join dept d using (deptno);등가(Equi) 조인

■ A 테이블의 키의 값과 B 의 값이 같은 레코드들을 테이블로 생성한다
/* equi join */ -- 조인 하는 두 테이블 모두에 같은 값이 있을 때만 보여준다 -- 가장 일반적으로 사용하는 조인(= 를 사용)이다 -- 1) ★ 등가 조인 -- 'kim' 이 어느 부서에 소속되어있는지 확인한다 -- 두 테이블에 같은 컬럼 같은 값이 있다면 그 레코드만 조회한다 select e.ename, d.deptname from emp e, dept d where d.deptno = e.deptno; insert into dept(deptno, deptname, loc) values ('5', 'dev02', 'florida'); create table test_b ( name varchar(5) ,id int(3) ); insert into test_b(name) values('lee'); select test_a, test /* 양쪽에 데이터 불균형이 있을 경우 * ename, deptname * (NULL), personnel * (NULL), dev02 * 이런 식으론 보여주지 않는다 */ select * from emp; select * from dept;내츄럴(Natural) 조인
■ 공통되는 컬럼을 알아서 찾아서 자연스럽게 합쳐주는 조인이다
■ 공통되는 컬럼명을 단축명으로 사용하지 말아야한다 ( 일부 데이터베이스에서는 오류가 발생한다 )
-- 3) 내츄럴 조인(자연스러운) -- 두 테이블 사이 공통되는 컬럼이 있으면 자연스럽게 합쳐지게 된다 -- 그래서 조인을 위한 조건절이 필요 없다 -- 주의사항 ) ★ 공통되는 컬럼명은 단축명을 사용하지 않는다!!!!!!!( 일부 db 에서는 에러 날 수 있음) select deptno, e.ename, d.deptname from emp e natural join dept d;셀프(Self) 조인
■ 자기 자신으로 두개의 테이블로 크로스 조인을 수행한 결과를 보여준다
-- 4) 셀프 조인 -- EQUI-JOIN 과 똑같다 다만 두개의 테이블이 둘다 자신이라는 것만 다르다 -- 셀프조인을 하면 자기 스스로의 두개의 테이블로 카다시안 곱을 수행한다 select a.ename, b.job from emp a, emp b where a.deptno = b.deptno;외부 조인

■ A, B 테이블 중 한쪽에만 키의 값을 기준으로 삼아 조인한 결과를 보여준다
■ FROM [table A] [left|right] outer join [table B] on [조건절]
■ LEFT (왼쪽 테이블의 키를 기준으로 테이블을 생성하여 보여준다)
■ RIGHT (오른쪽 테이블의 키를 기준으로 테이블을 생성하여 보여준다)-- 5) 외부 조인 -- 정보의 불균형이 있을때 사용하는 조인이다 -- [table A] [left|right] outer join [table B] on 조건절 -- LEFT (왼쪽을 기준으로 더 있는 값을 보여준다) -- RIGHT (오른쪽을 기준으로 더 있는 값을 보여준다) -- FULL (서로 없는 값을 보여준다) 우리는 지원하지 않는다 select * from dept; select e.deptno, e.ename, d.deptname from emp e right outer join dept d on e.deptno = d.deptno; select e.deptno, e.ename, d.deptname from emp e right join dept d on e.deptno = d.deptno; -- emp 에 deptno 6번을 추가 insert into dept(deptno) values('6'); insert into emp (deptno,ename,job,hiredate) values ('6', 'kim', 'assistant', str_to_date('14-06-02','%Y-%m-%d')); -- 연계 참조 무결성 제약조건에 의해서 부모에게 없는 6번을 자식이 넣을 수 없다 -- 그래서 부모-자식 관계를 해제해야한다 -> 외래키 제약조건을 삭제하는것을 말한다 -- 부모 자식 관계가 아니라고 해도 조인은 된다 alter table emp drop constraint emp_ibfk_1; select * from information_schema.TABLE_CONSTRAINTS where TABLE_NAME = 'emp'; select * from dept; /* * left join : join 을 기준으로 왼쪽 테이블의 데이터를 기준으로 보여준다 (오른쪽에 없는 내용은 null 처리) - 1, 2, 4, 6 * right join : join 을 기준으로 오른쪽 테이블의 데이터를 기준으로 보여준다 (왼쪽에 없는 내용은 null 처리) - 1,2,3,4,5 * 서로 없는 내용을 보여줄 수 있는 방법 : full outer join * -> mariadb 에서는 지원하지 않지만 방법이 다 있다 이말이다 */
집합
■ [첫번째 쿼리문] [UNION|UNION ALL|INTERSECT|MINUS] [두번째 쿼리문]
□ 중복 제거를 해주는 UNION 는 성능저하 문제로 권장하지 않는다
1) 합집합 : UNION
■ 두개의 집합을 합친 집합에서 중복을 제거한 집합을 말한다
-- 1) UNION : 중복을 제거한 합집합 -- 성능저하가 많이 생긴다 select deptno from emp UNION select deptno from dept order by deptno;1-1) FULL OUTER 조인
■ 두개의 테이블을 LEFT JOIN, RIGHT JOIN 한 결과를 UNION 로 조회할 수 있다
-- left join 과 right join 을 유니온하면 full outer join 효과를 얻을 수 있다 select e.deptno, e.ename, d.deptname from emp e left join dept d on e.deptno = d.deptno UNION select d.deptno, e.ename, d.deptname from emp e right join dept d on e.deptno = d.deptno;2) 합집합 (중복 허용 ) : UNION ALL
■ 두개의 쿼리문의 결과를 모두 합친 집합을 말한다
-- 2) UNION ALL : 중복 제거 없이 합집합 실행 -- UNION ALL 을 순수하게 실행한다기 보다는 정제해서 사용한다 -- 일단 합쳐 그 안에서 중복을 없애! -- 무언가 작업을 확 해버리고, 그 다음에 뭘 해! select deptno from emp union all select deptno from dept order by deptno;3) 교집합 : INTERSECT
■ 쿼리문으로 만들어진 양 테이블에 중복되는 데이터가 담긴 집합을 말한다
-- 3) INTERSECT : 양 테이블에 존재하는 중복된 데이터만 확인한다 select deptno from emp intersect select deptno from dept order by deptno;핵심. UNION 을 대체해보자
-- 5) union 을 대체할 경우? -- a) 일단 두개의 테이블의 데이터를 합친다 select deptno from emp union all select deptno from dept; -- b) 합친 데이터들을 가지고 중복을 제거한다 select distinct u.deptno from (select deptno from emp union all select deptno from dept) u order by u.deptno asc;1. 서브쿼리란?
2. 상호관계 서브쿼리란?
3. 조인이 뭔가요?
4. 크로스 조인 ㅁㅈ?
5. 크로스 조인의 역할?
6. 등가조인?
7. 등가는 ㅁㅈ?
8. 내츄럴 조인 ㅁㅈ?
9. 외부조인은 ㅁㅈ?
10. 풀 아우터 조인뭘 사용 ? UNION
11. 고유 인덱스 ㅁㅈ?
12. IN 과 EXISTS 차이점
13. UNION 을 대체할
14. ANY, ALL
15. VIEW
'프로그래밍 언어 > 데이터베이스(SQL, MARIADB)' 카테고리의 다른 글
20일차 - 정규화 (0) 2024.02.22 19일차 - INDEX, IN, EXISTS, VIEW (1) 2024.02.19 17일차 - 컬럼의 제약조건 (0) 2024.02.15 16일차 - 트랜잭션과 관련된 명령문 (0) 2024.02.15 14,15일차 - 데이터베이스 DDL, DCL, DML (0) 2024.02.13